





As a result of the Blackwell B200 GPU and GB200 “superchip,” Nvidia has grown into a multitrillion-dollar company, potentially worth more than Alphabet and Amazon combined.

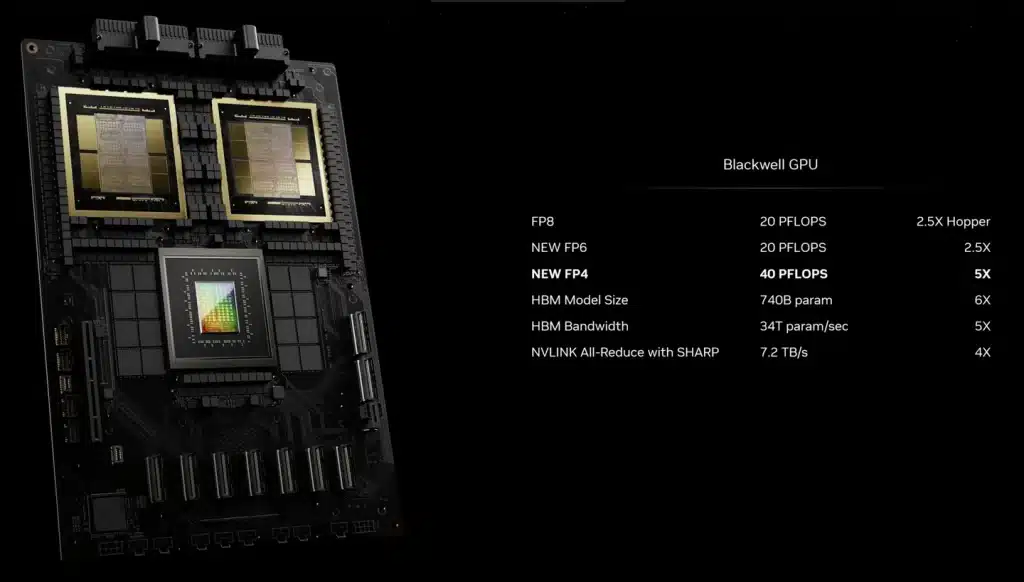
According to Nvidia, their latest B200 GPU boasts 208 billion transistors and can deliver up to 20 petaflops of FP4 power. Additionally, combining two of these GPUs with a single Grace CPU in the GB200 model offers a remarkable 30-fold increase in performance for LLM inference tasks. This combination also has the potential to greatly improve efficiency. In fact, Nvidia asserts that it can reduce costs and energy usage by as much as 25 times compared to the H100 model.
Previously, Nvidia claimed that training a 1.8 trillion parameter model would have required the use of 8,000 Hopper GPUs and consumed 15 megawatts of power. However, the company’s CEO now states that this can be achieved using only 2,000 Blackwell GPUs and consuming just four megawatts of power. Additionally, on a GPT-3 LLM benchmark with 175 billion parameters, the GB200 offers seven times the performance of an H100 and four times the training speed according to Nvidia.

During their presentation to journalists, Nvidia shared details about their latest advancements. They mentioned a second-generation transformer engine which uses only four bits per neuron instead of eight, effectively doubling the compute, bandwidth, and model size. This explains the impressive 20 petaflops of FP4 previously mentioned. Additionally, Nvidia has implemented a next-generation NVLink switch that allows for communication between 576 GPUs with a bidirectional bandwidth of 1.8 terabytes per second. To achieve this feat, they had to create a new network switch chip with 50 billion transistors and its own onboard compute power of 3.6 teraflops of FP8.
According to Nvidia, previously a group of 16 GPUs would spend the majority of their time communicating rather than computing. Naturally, Nvidia is anticipating that businesses will purchase these GPUs in bulk and has created larger configurations such as the GB200 NVL72. This rack contains 36 CPUs and 72 GPUs, all liquid-cooled, for a combined AI training performance of 720 petaflops or an impressive 1,440 petaflops (also known as 1.4 exaflops) of inference. The rack boasts approximately two miles of internal cables and consists of a staggering amount of 5,000 individual wires.

Nvidia has announced that each rack houses a combination of two GB200 chips and two NVLink switches, with 18 sets of the former and nine groups of the latter per rack. This configuration allows for a 27-trillion parameter model, potentially including the rumored GPT-4 which is estimated to have 1.7 trillion parameters. Major players like Amazon, Google, Microsoft, and Oracle are reportedly planning to include Nvidia’s NVL72 racks in their cloud services, although specific quantities have not been disclosed. Additionally, Nvidia offers the complete solution with their DGX Superpod for DGX GB200, consolidating eight systems into one for an impressive 288 CPUs, 576 GPUs, 240TB of memory, and computing power of 11.5 exaflops on FP4.

According to Nvidia, their systems are capable of supporting large numbers of GB200 superchips by utilizing either the Quantum-X800 InfiniBand (up to 144 connections) or the Spectrum-X800 ethernet (up to 64 connections), with a networking speed of 800Gbps. Today’s news is not expected to include any updates on gaming GPUs, as this announcement is from the GPU Technology Conference, which typically focuses on computing and AI rather than gaming. However, we can anticipate that the Blackwell GPU architecture will also be used in upcoming RTX 50-series desktop graphics cards.
Source: The Verge
